


版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
前沿
这几天ChatGPT可谓是热火朝天,很多同事和朋友都来找到勇哥,说能不能说一说相关话题,但是之前几天勇哥都在默默的干一件大事情,今天终于成型、有结果了,所有就抽了点时间来和大家一起聊聊ChatGPT背后的技术,让大家对一自然语言处理背景的技术有一个入门级别的了解。
阅读本文你的收获★★★
-
了解到ChatGPT是什么、有哪些功能?
-
了解到ChatGPT背后自然语言技术有那些?
-
了解到一般AI系统的工作流程
老规矩,你觉得本文不错,点赞、关注一下,鼓励鼓励勇哥!
ChatGPT简介
ChatGPT是OpenAi 在12 月 1 日上线的一套在线人机聊天产品,而这套产品这几天已经突破上100万的,可谓是火得不要不要的了,但勇哥总结其火的背后主要有这么几方面的因素:
-
OpenAi 背后的大佬是微软
-
ChatGPT之别被姓马的夸赞,起到了很好的宣传
-
OpenAi 这套产品自身从技术+架构方面有新的突破
-
各位网友心中都有一个未来科技梦
-
ChatGPT不对中国区开放,但是支持中文(这点细品....)
在这里勇哥主要站在产品自身的技术和架构方面的突破来给大家说一说,先说一说ChatGPT能做什么,我简单的归类了一下功能,包括:
-
知识问答
-
知识点解答
-
数学题求解
.....
-
-
文学创作
-
写作文
-
写诗
-
写小说
-
写邮件
......
-
-
程序创作
-
写代码
-
改BUG
......
-
ChatGPT技术★★★
下面这张图是OpenAi官网上的一张说明图,但是这张图只说明了其系统的模型(PS:这里的模型大家可以简单理解成一对特殊的数据)训练和应用流程:
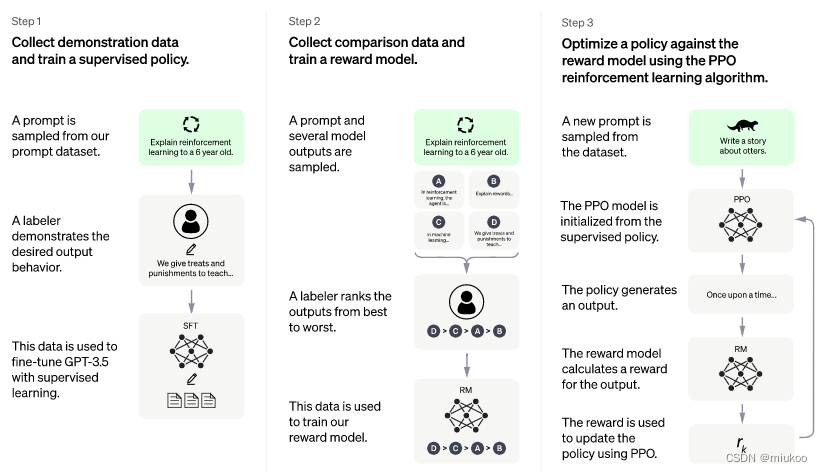
上图并没有说明太多这样系统的技术架构,那么勇哥在这里来给大家脑补一下,一般这种系统的数据流是如何进行流转的:
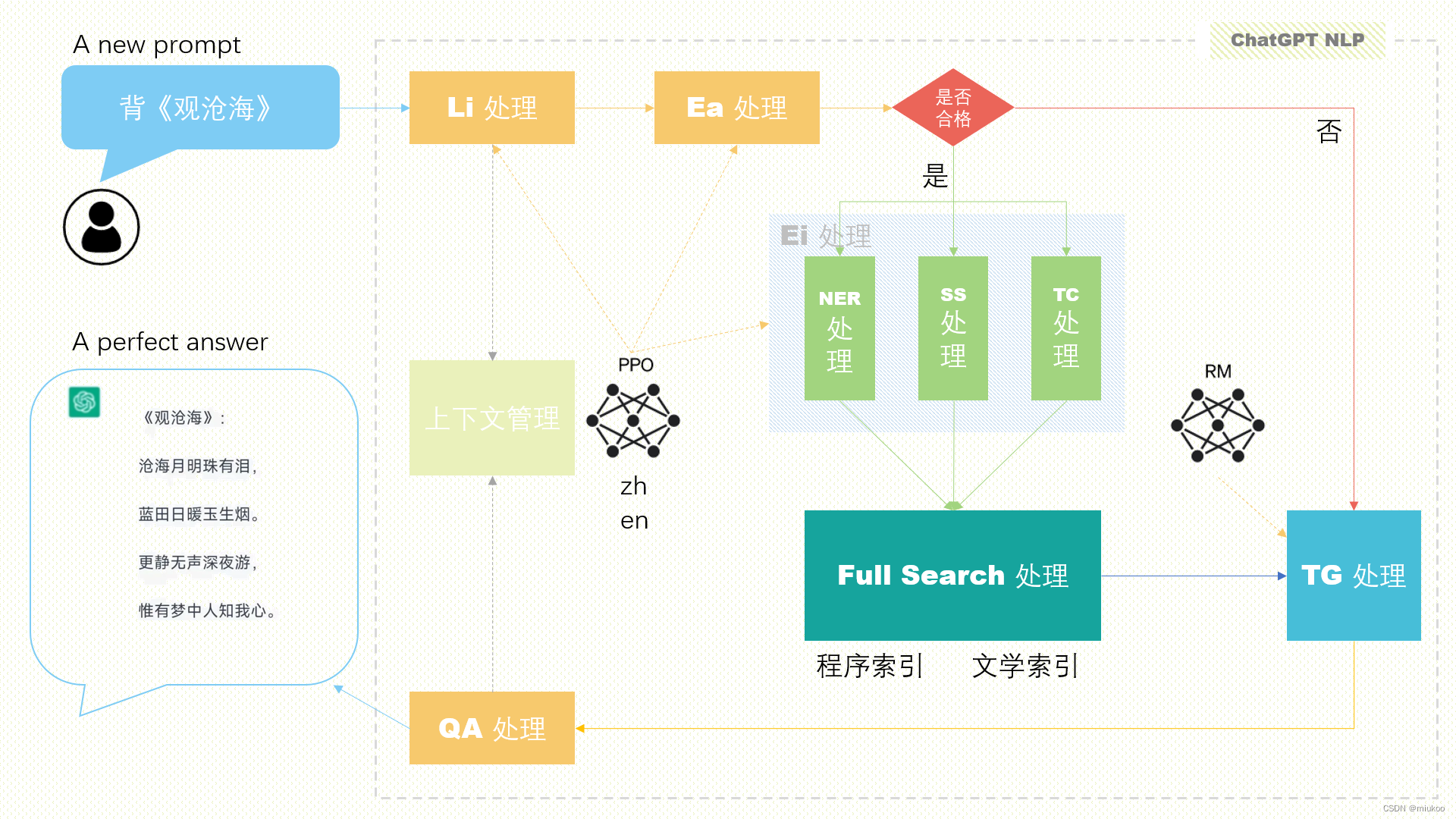
数据流说明:
ChatGPT是一个聊天系统,用户输入一句话,那么ChatGPT就需要依据用户输入的信息反馈相关内容,比如上述用户输入“背《观沧海》",系统接收到信息后,就经过以下处理,来为用户生产相对准确的答案:
-
Li处理:既语言识别(Language identification),ChatGPT是面向中国区之外的用户,因此用户输入的信息有多种语言,至于是那种语言需要先进行识别。识别之后既可以确定在PPO中使用的是中文、还是英文、还是其它模型数据。
-
Ea处理:既情感分析(Emotional analysis),ChatGPT对于输入信息进行了多中情感分析,如果情感不符合正能量方面的要求,ChatGPT会自动拒绝回答相关用户问题。这点也是非常必要的。Ea处理也需要基于PPO模型库来分析计算。
-
Ei处理:既抽取信息 (Extract information),从用户输入的信息中提取关键特征,为下一步准备数据
-
NER处理:既命名实体识别(Named entity recognition),负责提取其中的人名、地名、专业术语等信息
-
SS处理:既句子相似性处理(Sentence Similarity),用户输入的信息可能存在错别字等信息,通过此步可以进行一个修正
-
TC处理:既文本分类(Text Classification),把用户输入得信息进行分类,通过此步分类,好定位到下一步搜索用到的相关搜索索引
-
-
Full Search 处理:既全文搜索处理,ChatGPT是一个自然语言+搜索引擎集成的架构,通过Ei处理得到的数据就是全文搜索的输入数据,比如EI提取出 NER=观沧海,SS=,TC=文学,那么此步就可以去搜索文学索引中的《观沧海》,得到想要的答案。
-
TG处理:既文本生成(Text Generation),上一步搜索的结果可能有多条数据,那么那一条最符合用户需求呢?则通过RM模型来进行选取,选取后生成对应的文本内容。
-
QA处理:既问题解答(Question Answering),把上一步生成的答案进一步转换成适合问答的形式或格式。
总结:
ChatGPT总体架构技术是:NLP是核心 , 搜索辅助,算力是硬核
NLP : 上述流程描述中:Li、Ea、Ei、NER、SS、TC、TG、QA等处理,都需要依赖ChatGPT自身的GPT-3.5自然语言模型数据,而且按照上述流程执行,流程步骤长,上一步的结果就是下一步的输出,一步出错,结果必错。ChatGPT能做到现在这样已经是相当的了不起了。NLP自然就是ChatGPT的核心了。
搜索:一般自然语言处理后的特征数据,是句子或者词组,对此搜索,常规的搜索肯定不行,而全文搜索技术自然就成为首选,比如开源流行的Elasticsearch,在里面主要存储了大量的问题答案、范本数据等。
算力:告诉大家一个事实:一般一个NLP模型数据非常大,上G上T都是非常正常的事情;那么这么大的数据量,每次搜索都要进行与其计算,普通的CPU肯定是更不上的,因此GPU是首选,而且最好是使用云上的GPU算力,才能收缩性更得上。





