
机器学习当中,参数越多,理论上的精度越高(也极易产生过拟合),当然需要的算力也更多,GPT-3 使用了惊人的 1750 亿参数,堪称史上最大 AI 模型,没想到这才多久,Google Brain 团队就搞了一个大新闻,他们使用了 1.6 万亿参数推出了语言模型 Switch Transformer,比 T5 模型当中的 T5-XXL 模型还要快4倍,比基本的 T5 模型快了 7 倍。
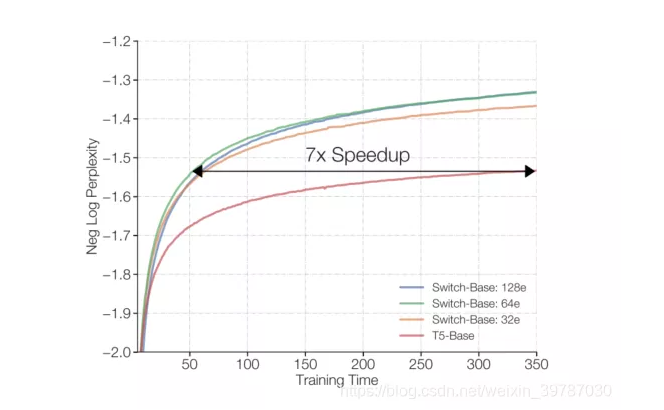
近日,Google Brain 团队在预印本发布论文《SWITCH TRANSFORMERS: SCALING TO TRILLION PARAMETER MODELS WITH SIMPLE AND EFFICIENT SPARSITY》,宣布利用万亿级参数进行预训练的稀疏模型 SWITCH TRANSFORMERS 的诞生,该方法可以在控制通信和计算资源的情况下提升训练的稳定性,同等计算资源条件下比 T5-XXL 模型快 4 倍。来自 Google Brain 的三位科学家 William Fedus、Barret Zoph 以及 Noam Shazeer 使用了 Switch Transformer 模型,简化了 MOE 的路由算法、设计了直观的改进模型,从而实现了通信和计算成本的降低。值得期待的是,这种训练方法修复了不稳定性,并且首次展示了大型稀疏模型在低精度(bfloat 16)格式下进行训练。将模型和 T5 模型进行对比,基于 101 种语言的设置和 C4 语料库(Colossal Clean Crawled Corpus,从网络上抓取的数百 GB 干净英语文本) 训练效果实现了对 T5 模型的超越,甚至是 7 倍速碾压。
模型原理
深度学习模型通常对于所有的输入重复使用相同的参数,而专家混合模型(Mixture-of-Experts)则不是这样,它采用的模式是对输入实力选择不同的参数。这样的结果就是可以在计算成本不变的情况下得到一个稀疏激活模型,它的参数可以是无比巨大的。然而 MOE 具有较大的通信成本,且训练不稳定,因而难以推广。简单来说,Google Brain 基于 MOE 推出了一种方案,利用稀疏模型增加速度,对于需要稠密模型的时候也可以将稀疏模型蒸馏成稠密模型,同时进行微调,调整 dropout 系数避免参数过大的过拟合。
关于 MOE
混合专家系统属于一种集成的神经网络,每一个专家就是一种神经网络,我们查看特定案例的输入数据来帮助选择要依赖的模型,于是模型就可以选择训练案例而无需考虑未被选中的例子,因此他们可以忽略不擅长的建模内容。它的主要思想就是让每位专家专注于自己比其他专家更优的内容。这样一来,整体的模型就趋于专业化,如果当中的每个专家都对预测变量求平均,那么每个模型就都要去补偿其他模型产生的综合误差。所谓“术业有专攻”,专家就让他去搞专业的事情。
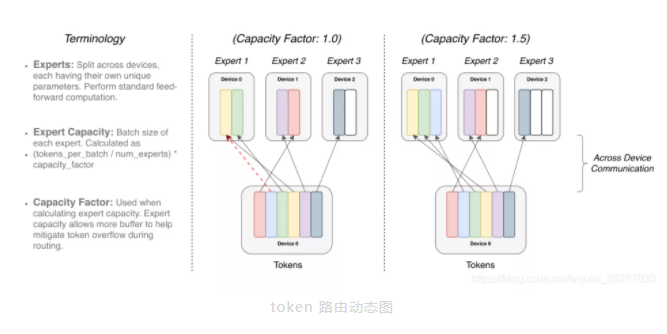
token 路由动态图在这个模型当中,每个专家处理固定的批量 token 容量系数,每个 token 被路由到具有最高路由概率的专家,但是每个专家的批处理量大小是(token 总数/专家总数)×容量因子,如果 token 分配不均,某些专家就会超载,大的容量系数可以缓解流量问题,也会增加通信成本。
权重分配与近水楼台
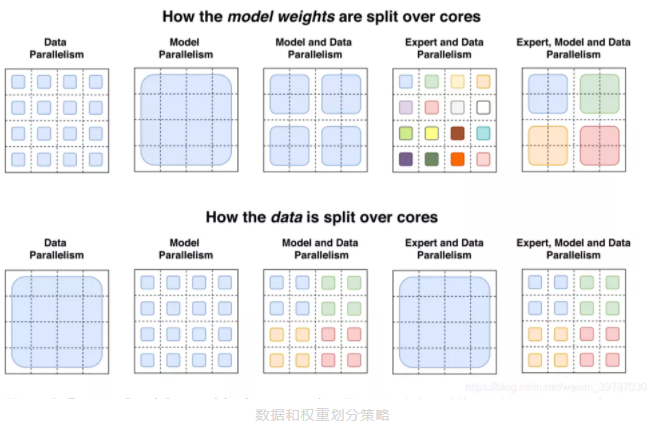
每个 4×4 的虚线网格表示 16 个核,阴影正方形是该核上包含的数据(模型权重或令牌批次)。我们说明了如何为每种策略拆分模型权重和数据张量。第一行:说明模型权重如何在核心之间分配。此行中不同大小的形状表示前馈网络(FFN)层中较大的权重矩阵。阴影正方形的每种颜色标识唯一的权重矩阵。每个核心的参数数量是固定的,但是较大的权重矩阵将对每个令牌应用更多的计算。第二行:说明如何在内核之间拆分数据批。每个内核持有相同数量的令牌,从而在所有策略中保持固定的内存使用率。分区策略具有不同的属性,允许每个内核在内核之间具有相同的令牌或不同的令牌,这是不同颜色所象征的。同时,该模型对于稠密矩阵乘法适应硬件进行了有效利用,比如 GPU 和 Google 自家的 TPU,早在 2019 年,Google AI 就模拟了果蝇东岸从的神经图,由于扫描后重建图像高达 40 亿像素,为了处理这些图片,Google AI 使用数千块 TPU 进行计算处理,可以说是下了血本。而此次推出的模型,它需要最低的硬件标准只是满足两个专家模型的需要就够了。
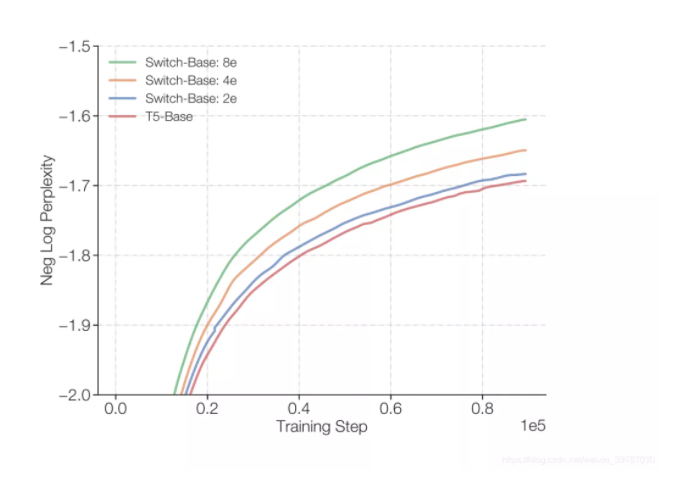
如上,满足两个专家的模型,仍然能够对 T5-Base 模型有所提升。
跑个分~
之前介绍到,Google Bain 当时的 T5 组合模型霸榜过 SuperGLUE,该模型在语言模型基准测试榜 GLUE 和 SuperGLUE 上得分均不同程度地超过 T5 的基础水平,也算是正常发挥。
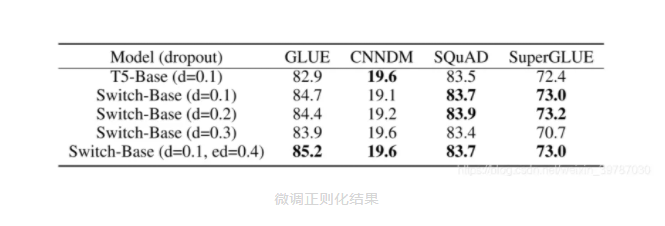
虽然模型距离目前榜首的 DeBERTa 组合模型还有较长的一段路要走,该项目最大的意义在于实现了超大型参数和稀疏模型结合的高效使用,
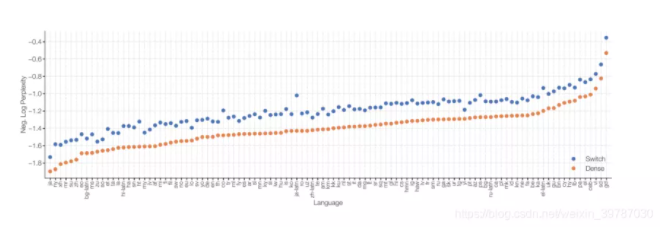
下游实验中,我们进行了 101 种语言的测试,可以看到该模型相比稠密模型,在所有的任务上均有明显提升。
当场答疑
31 页的论文,难免有读者看完之后有好奇或不解,作者想到了这个问题,直接写了出来。作者强调,在稀疏专家模型当中,“稀疏” 指的是权重,而不是关注模式。
-
纯粹的参数技术会让 Switch Transformer 更好吗?
是的,看怎么设计!参数和总的 FLOPs 是独立衡量神经语言模型的标准。大型模型已经被证实具有良好的表现,不过基于相同计算资源的情况下,我们的模型具有更加简洁、有效且快速的特点。
-
我没有超算——模型对我来说依然有用吗?
虽然这项工作集中在大型模型上,我们发现只要有两个专家模型就能实现,模型需要的最低限制在附录当中有讲,所以这项技术在小规模环境当中也非常有用。
-
在速度-精度曲线上,稀疏模型相比稠密模型有优势吗?
当然,在各种不同规模的模型当中,稀疏模型的速度和每一步的表现均优于稠密模型。
-
我无法部署一个万亿参数的模型-我们可以缩小这些模型吗?
这个我们无法完全保证,但是通过 10 倍或者 100 倍蒸馏,可以使模型变成稠密模型,同时实现专家模型 30%的增益效果。
-
为什么使用 Switch Transformer 而不是模型并行密集模型?
从时间角度看,稀疏模型效果要优越很多,不过这里并不是非黑即白,我们可以在 Switch Transformer 使用模型并行,增加每个 token 的 FLOPs,但是这可能导致并行变慢。
-
为什么稀疏模型尚未广泛使用?
扩展密集模型的巨大成功减弱了人们使用稀疏模型的动力。此外,稀疏模型还面临一些问题,例如模型复杂性、训练难度和通信成本。不过,这些问题在 Switch Transformer 上也已经得到了有效的缓解。
论文很长,深入了解,还需阅读全文。
参考资料:https://arxiv.org/pdf/2101.03961.pdf项目代码地址:https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.py








